
【例题 ctfshow pwn82】
# 1. 用处:
在有溢出而无法泄露内容时可以利用 ret2dlresolve 来修改解析的函数,从而达到执行想要的函数的目的
# 2. 原理:
程序通过动态链接来达到节省空间的目的,动态链接会有一个延迟绑定的特点,将连接的过程推迟到了程序运行时
动态链接中有个重要函数 _dl_runtime_resolve(link_map_obj,reloc_index) 来对动态链接的函数进行重定位
利用dl_resolve原因:
1、dl_resolve 函数不会检查对应的函数是否越界,它只会根据我们给定的数据来执行(也就是说其可以偏移到我们构造的地方)
2、dl_resolve 函数最后的解析根本上依赖于所给定的字符串(修改其要解析的字符串也就会调用修改后的函数)
dl_runtime_resolve 函数只会在第一次调用这个动态链接的函数时其作用,第二次调用就不需要解析了,可以直接得到这个调用的函数的地址;
第一次调用时程序会查找需要链接的各种信息,再通过 _dl_runtime_resolve 将函数的真实地址写入 got.plt 表中
# 1. 运行 _dl_runtime_resolve 前
在第一次调用动态链接函数前程序执行的是 *.plt 函数,其内部会执行 dl_runtime_resolve 来进行解析找到真实地址
这里看一下第一次调用 write 函数的情况(实际上第一次调用的是 write@plt 的形式)利用命令 objdump -d pwn82

得到第一次调用 write 的地址,在 gdb 中下断点 b *0x80485a6 ,然后运行

si 单步进入 write@plt 查看情况:
发现最后执行了 _dl_runtime_resolve , got.plt 内放的是要跳转执行的下一条汇编指令地址

分析具体调用方法:
- 进入 write 自己的表项后,有个 push 0x20 是
dl_runtime_resolve(link_map_obj,reloc_index)的第二个参数 `reloc_index - 进入公共 plt 表项 (plt0) 后,有个 push <0x80498bc> 就是第一个参数
link_map_obj
这里我们需要将 plt0 的地址覆盖到 ret 处,也就是执行了跳转,同时将 dl_runtime_resolve 的第一个参数 push 进栈【这么做的原因是因为我们需要利用 dl_runtime_resolve 函数解析执行我们需要的函数,直接 ret 进入会缺少第一个参数,用自己的 plt 表项覆盖 ret 就无法偏移到我们想要的地址】
这里利用ret0覆盖ret后,需要直接写入参数"reloc_index",因为这是通过模拟这种方式执行write_plt等函数(可以将这两个整体视为调用了函数),需要手动写入参数到栈上,后面就是调用write_plt的返回地址和参数
最终也就是:p32(plt0)+p32(reloc_index)+p32(返回地址)+p32(参数1)+p32(参数2)+p32(参数3)
# 疑问
为什么要以 plt0 覆盖 ret,而不直接用 dl_runtime_resolve 来覆盖
因为需要填充 dl_runtime_resolve 的参数,而我们执行 plt0 就不需要填充第一个参数了,而第二个参数是我们需要控制的所以需要自己填充
# 2. 执行 _dl_runtime_resolve
在上面的两个 push 中将 _dl_runtime_resolve 的两个参数压入栈中,然后就进入 _dl_runtime_resolve 来执行
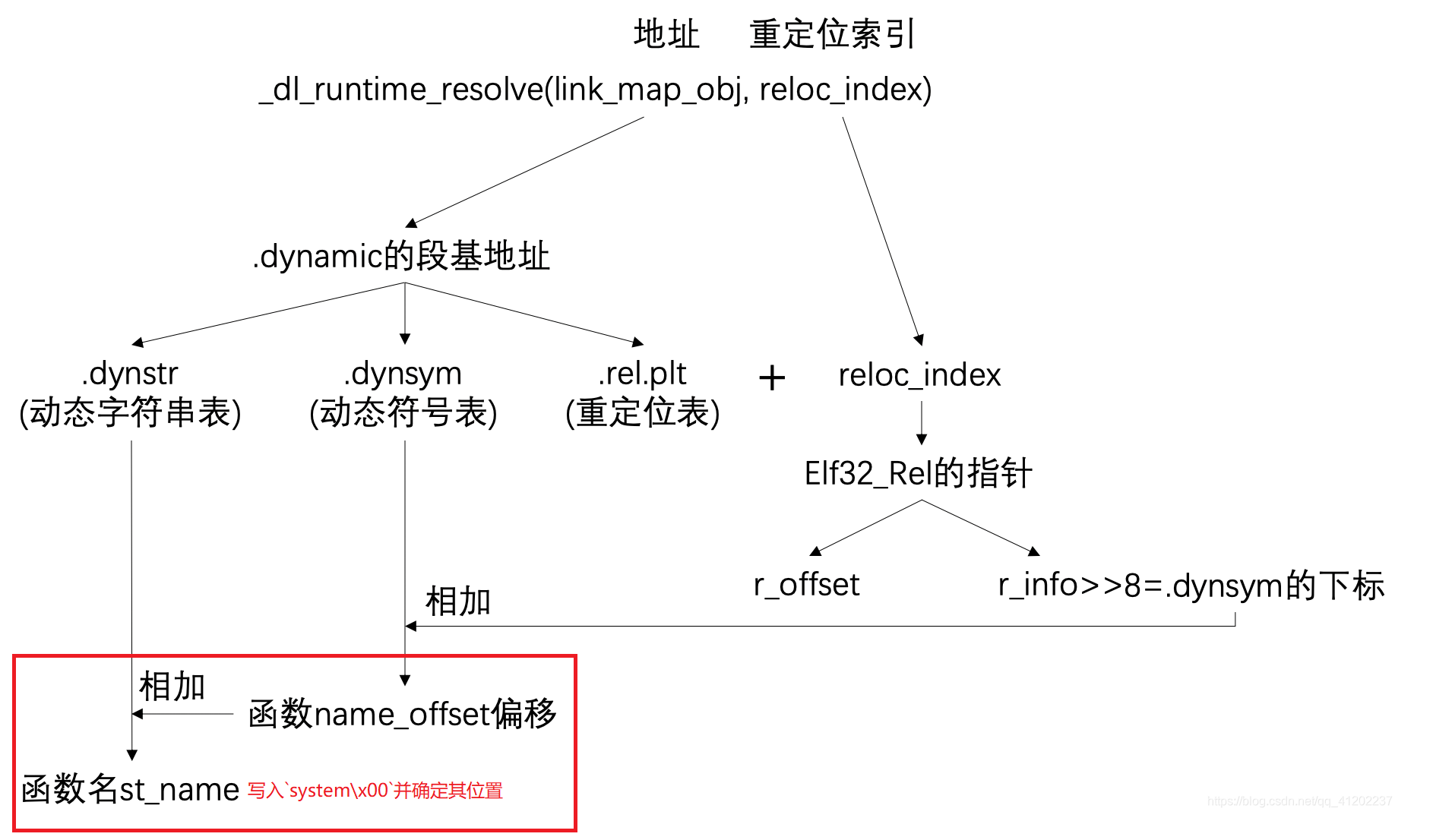
其内部过程为 (借用大佬的图):
通过上面的图可以看到以第二个参数为准,然后一步一步相加计算得到要解析的函数名
# 第一步:得到 reloc_index
利用第二个参数与 .rel.plt 相加,那么就可以得到调用的函数的具体 .rel.plt 结构体情况:
.rel.plt 结构体:
typedef struct{ | |
Elf32_Addr r_offset; | |
Elf32_Word r_info; | |
}Elf32_Rel |
从上面的 .rel.plt 结构体来看, .rel.plt 重定位表 是保持了所有函数的这个结构体信息(每个结构体 8 字节),而不仅仅是起到一个索引的作用
因此用 .rel.plt 的基地址加上 偏移 就为所要函数的 Elf32_Rel 指针,然后就得到了对应的 r_offset 和 r_info
.rel.plt 存放内容 (命令 readelf -x .rel.plt 程序名 ):

我们的重点就是在这个 偏移 如何得到:
上面可以知道在执行时,第二次跳转到 plt0 (.plt 表的头部),而我们需要的是 .rel.plt 这里就有一个对应的关系(这里就要计算得函数是.plt 的第几个结构体,)
上面可以看到,对应结构体开始在 .plt 中是从下标 1 开始,而在 .rel.plt 中是从下标 0 开始,也就是说如果 write 结构体是结构体 5,那么在 .rel.plt 中就是结构体 4
.plt 存放内容 (命令 readelf -x .plt 程序名 ):
通过上面的对应关系知道,我们想要找 write 在 .rel.plt 重定位索引就要通过 plt 来得到,由 .plt 与 .rel.plt 的对应关系知道: plt结构体-1=rel.plt结构体 ,所以这里计算在.plt 中是第几个结构体:
write_plt-plt[0]=offset //这里plt[0]地址可以通过pwntools得到
offset/16=是plt表中的第几个结构体
plt结构体-1=rel.plt结构体
因为.rel.plt结构体的大小为8字节,所以还要乘8(这里得到的值是相对偏移)
也就是:
write_index = [(write_plt-plt[0])/16 -1] * 8(write_index就是与.rel.plt的偏移,也就是reloc_index)【不过其实这个计算再后面伪造时用不到,因为偏移通过后面伪造的地址减基地址就得到了】
# 第二步:伪造 .rel.plt 结构体
上面知道 write_index 知道,这是与 .rel.plt 的偏移;但是在 dl_resolve 执行时并没有检查边界,所以我们可以将这个偏移任意修改,因此可以修改其偏移到到我们伪造的 .rel.plt 结构体,可以构建式子:
rel.plt+write_index=fake_struck_rel_plt
所以:
write_index=fake_strunk_rel_plt-rel.plt
然后需要考虑在偏移的地方来伪造对应的结构体:
typedef struct{ | |
Elf32_Addr r_offset; | |
Elf32_Word r_info; | |
}Elf32_Rel |
这个结构体有两个成员变量需要伪造,第一个是 r_offset ,这个可以通过 pwntools 的 ELF 功能自动获得,也就是 write_got=elf.got["write"] ;第二个成员变量 r_info 需要自己查看 readelf -a 程序名 ,如下:
看下面的图可以知道, r_info 右移一个字节,以上图中的 607 的 6 作为.dynsym 下标,寻找.dynsym 的标号为 6 结构体 (下标以 0 开始)
# 第三步:构造动态符号表 dynsym+(r_info>>8)
dynsym 结构体:
typedef struct | |
{ | |
Elf32_Word st_name; // 符号名,是相对.dynstr 起始的偏移 | |
Elf32_Addr st_value; | |
Elf32_Word st_size; | |
unsigned char st_info; // 对于导入函数符号而言,它是 0x12 | |
unsigned char st_other; | |
Elf32_Section st_shndx; | |
}Elf32_Sym; // 对于导入函数符号而言,除 st_name 外其他字段都是 0 |
所以根据该结构体,我们要伪造的结构体样子大致为 [name偏移,0,0,0x12]
l 利用命令 readelf -a pwn82 找到 .dynsym 符号表,可以看到 write 对应的是下标 Num=6
接下来查看具体 write 的 .dynsym 结构体:
其结构体就是 [0x4c,0,0,0x12] (当然这里的 0x4c 可以被改变,这就达到解析其他字符串的目的),而在 dynsym+(r_info>>8) 也就是得到了该结构体,我们可以修改 r_info 使下标指向到我们伪造的 dynsym 结构体处
伪造 .dynsym 结构体:
因为 .dynsym 的每个结构体大小是 16 字节,那么我们就需要满足其是 16 字节对齐的(因为这里是以下标的形式索引每次只能 16 字节的查找,其他的直接用偏移所以不用担心对齐),利用公式使其满足 16 字节对齐:
fake_sym_addr = base_stage + 32 //伪造结构体的地址
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf) //计算是否是16字节对齐
fake_sym_addr = fake_sym_addr + align //使完成16字节对齐
# 疑问 1
0x10 - ((0x8048a88 - 0x8048a00) & 0xf) = 0x10 - 0x8 = 0x8
距离初始的偏移,然后与0xf查看最后一16进制位的值,0x10来看其满足16进制对齐还有多少距离
接下来利用伪造的 .dynsym结构体 来反推 r_info :
我们知道 dynsym+(r_info>>8)=write结构体地址 ,而在我们伪造的结构体下已知了结构体地址,所以:
index_dynsym = (fake_sym_add-dynsym ) / 0x10(间隔的结构体个数)
r_info=(index_dynsym<<8)+0x07
这里得到的 r_info 就可以在前面伪造的 .rel.plt 结构体处使用这个值( r_offset 不用改变)
# 第四步:构造动态字符表 (.dynstr)
这里我们需要构造两部分
- 构造
.dynstr动态字符表 (也就是部署write\x00这个字符串去解析) - 修改第三步中的
.dynsym结构体的str_name这个偏移量(使能够找到 write 字符串)
首先就是部署 write\x00 字符串,得到这个的地址记为 fake_write_addr ,接下来计算偏移 str_name=fake_write_addr-dynstr ,最后将第三步中的 dynsym 结构体伪造成 [str_name,0,0,0x12]
# 第五步:getshell
上面部署的是 write\x00 字符串,那么我们下面将其部署成 system\x00 就可以了,而 write 函数的三个参数中,将第一个参数修改为 /bin/sh\x00 就能 getshell
# 3. 总结:
ret2dlresolve 是在无法泄露地址得到 libc 的情况下使用,这里是通过调用其他函数的 plt,之后在解析时解析我们想要执行的函数名即可
# 执行流程:
1. 首先通过重定位索引 reloc_index 来确定需要的函数在重定位表 .rel.plt 的偏移是多少,以此来找到对应的 Elf32_Rel 结构体
构造步骤:
- 部署字符串(要执行的函数名,如
system\x00) - 通过
字符串地址-dynstr基地址得到 dynsym 结构体中第一个成员变量的值(也就是字符串的偏移) - 部署伪造的 system 的
.dynsym结构体,其中第一个成员变量要用步骤2的值 - 由伪造的
system结构体地址 - dynsym 基地址 = 偏移,利用该偏移得到r_info((偏移 / 0x10<<8)+0x7) - 伪造
rel.plt结构体,通过上面的r_info作为其第二个成员变量(第一个成员变量为write_got等) - 利用伪造的
rel.plt结构体地址 - rel.plt 基地址 =reloc_index,得到的reloc_index就是dl_runtime_resolve第二个参数,第一个参数是link_map_obj在前面利用plt0覆盖 ret 后就直接 push 进栈了
# 疑问 1
有个疑问,为什么要分成三个表,直接是动态字符串表加偏移不行吗
个人觉得这是为了节省一定的资源,能够缩小一定的查找范围
# 疑问 2
.plt0 、 .rel.plt 、 .dynsym 、 .dynstr 的基地址怎么找:
plt0=elf.get_section_by_name(".plt").header.sh_addr
rel_plt = elf.get_section_by_name('.rel.plt').header.sh_addr
dynsym = elf.get_section_by_name('.dynsym').header.sh_addr
dynstr = elf.get_section_by_name('.dynstr').header.sh_addr
# 疑问 3
r_offset 的作用是什么,好像除了保持函数在 got 表的偏移就没有用了,这个偏移也就是 write_got = elf.got['write'] ,个人理解其作用是将 write 函数填入,不直接填入 system 是因为没有调用 system_plt ,通过这种方式进入 dl_runtime_resolve 最后改将解析的 write 变为 system 即可
# 疑问 4
r_offset 是 write_got = elf.got['write'] 而再调用过 write_plt 和未调用过 write_plt 情况下 write_got 是否相同?
第一次调用时才进行解析,后面调用时 write_got 里直接存放的是真实地址,那么我认为 r_offset 保持的不是真实地址,而是第一次调用时需要的偏移(那么我们再构造的时候用 write_got 是不是就有问题,因为感觉不是第一次调用得到的偏移)
# 注意的点
.dynsym 结构体下标以 0 开始 (其实就是除了 plt 之外其他的结构体但是从 0 开始的,因为 plt0 相当于作为头部了)
flat 函数是 pwn 模块的功能:将多个变量转化为二进制字符串
payload=pwn.flat([v1,v2,v3])
v1,v2,v3 是加入到 payload 的变量,相当于 v1+v2+v3
# 还要注意
我们执行的 plt [0] 等,需要是在迁移后的栈上执行,这里直接覆盖 ret 貌似有点问题
# 4. 例题(pwn82)
# 1. 程序信息:

main()函数 :
show()函数:
可以看到 read 函数能溢出,因为这道题有 write 函数,所以我们可以利用 ret2libc,但是这里换个方式用 ret2dlresolve 解决
# 2. 分析
通过上面的原理我们知道,需要构造一系列的结构体然后利用 _dl_runtime_resolve 的第二个参数 reloc_index 来最终通过构造的结构体找到想执行的函数名去解析 执行
而由于我们的构造的结构体内容需要指向后面构造的内容所以我们可以从后往前构造:
# 1. 首先确定 name_offset
将构造的 system 输入到 bss 段上
b"a"+read+p32(0)+p32(0x804+4)+p32(4)+read(0,98e0,len(dynstr))+read(0,8e0+0x100,len("/bin/sh"))+p32(0x8048376 plt0)+p32(0xdeadbeff)+p32(0x80498e0+0x100)