
# 概述
沙盒机制也就是我们常说的沙箱,英文名sandbox,是计算机领域的虚拟技术,常见于安全方向。一般说来,我们会将不受信任的软件放在沙箱中运行,一旦该软件有恶意行为,则禁止该程序的进一步运行,不会对真实系统造成任何危害。
在ctf比赛中,pwn题中的沙盒一般都会限制execve的系统调用,这样一来one_gadget和system调用都不好使,只能采取open/read/write的组合方式来读取flag。当然有些题目可能还会将上面三个系统调用砍掉一个,进一步限制我们获取到flag.
# 1.prctl函数调用
prctl是进程管理函数,沙箱规则通过prctl函数实现(也可以通过seccomp库函数实现),由它决定了哪些系统调用函数能被调用哪些不能被调用
// 函数原型
#include <sys/prctl.h>
int prctl(int option, unsigned long arg2, unsigned long arg3, unsigned long arg4, unsigned long arg5);
option选项有很多,剩下的参数也由option确定,这里介绍两个主要的option
PR_SET_NO_NEW_PRIVS(38) 和 PR_SET_SECCOMP(22)
/* Get/set process seccomp mode */
#define PR_GET_SECCOMP 21
#define PR_GET_SECCOMP 22
/*
* 用22时一般只允许 read、write、exit、sigereturn 函数执行
* If no_new_privs is set, then operations that grant new privileges (i.e.
* execve) will either fail or not grant them. This affects suid/sgid,
* file capabilities, and LSMs.
*
* Operations that merely manipulate or drop existing privileges (setresuid,
* capset, etc.) will still work. Drop those privileges if you want them gone.
*
* Changing LSM security domain is considered a new privilege. So, for example,
* asking selinux for a specific new context (e.g. with runcon) will result
* in execve returning -EPERM.
*
* See Documentation/userspace-api/no_new_privs.rst for more details.
*/
#define PR_SET_NO_NEW_PRIVS 38
#define PR_GET_NO_NEW_PRIVS 39
//为38时一般禁用 execve1.option为22的情况(#define PR_GET_SECCOMP 22)
第二个参数为1,只允许调用read/write/_exit(not exit_group)/sigreturn这几个syscall(系统调用):prctl(22,1LL,&V1)- 第二个参数为2,则为过滤模式,其中对syscall的限制通过参数3的结构体来自定义过滤规则:
prctl(22, 2LL, &v1);(第二个参数为2时,则会利用参数3的指向的sock_fprog结构体的成员指向的sock_filter定义的规则来进行过滤任意系统调用和系统调用参数,通过这种方式我们可以自己定义想要过滤的系统调用)
2.option为38的情况(#define PR_SET_NO_NEW_PRIVS 38)
第二个参数设置为1,则禁用execve系统调用且可以通过fork()函数和clone()函数继承给子进程:prctl(38, 1LL, 0LL, 0LL, 0LL);第二个参数设置为2,则为过滤模式,其中对syscall的限制通过参数3的结构体来自定义过滤规则
# BPF过滤规则(伯克利封装包过滤)
上面提到的PT_SET_SECCOMP这个参数,后面接到的第一个参数,就是它设置的模式,第三个参数,指向sock_fprog结构体,sock_fprog结构体中,又有指向sock_filter结构体的指针(struct sock_filter *filter; /*指向包含struct sock_filter的结构体数组指针*/),sock_filter结构体这里,就是我们要设置规则的地方
这里利用别人定义的sock_filter:
#include<stdio.h>
#include<fcntl.h>
#include<unistd.h>
#include<stddef.h>
#include<linux/seccomp.h>
#include<linux/filter.h>
#include<sys/prctl.h>
#include<linux/bpf.h> //off和imm都是有符号类型,编码信息定义在内核头文件linux/bpf.h
#include<sys/types.h>
int main()
{
struct sock_filter filter[]={ //结构体数组
BPF_STMT(BPF_LD|BPF_W|BPF_ABS, 0), // 从第0个字节开始,传送4个字节
BPF_JUMP(BPF_JMP|BPF_JEQ, 59, 1, 0), // 比较是否为59(execve 的系统调用号),是就跳过下一行(进入到下面的异常处理),如果不是,就执行下一行,第三个参数表示执行正确的指令跳转,第四个参数表示执行错误的指令跳转
BPF_JUMP(BPF_JMP|BPF_JGE, 0, 1, 0),
// BPF_STMP(BPF_RET+BPF_K,SECCOMP_RET_KILL),
// 杀死一个进程
// BPF_STMP(BPF_RET+BPF_K,SECCOMP_RET_TRACE),
// 父进程追踪子进程,具体没太搞清楚
BPF_STMT(BPF_RET+BPF_K,SECCOMP_RET_ERRNO),
// 异常处理
BPF_STMT(BPF_RET+BPF_K,SECCOMP_RET_ALLOW),
// 这里表示系统调用如果正常,允许系统调用
};
struct sock_fprog prog={
.len=sizeof(filter)/sizeof(sock_filter[0]),
.filter=filter,
};
prctl(PR_SET_NO_NEW_PRIVS,1,0,0,0);
prctl(PR_SET_SECCOMP,SECCOMP_MODE_FILTER,&prog);//第一个参数是进行什么设置,第二个参数是设置的过滤模式,第三个参数是设置的过滤规则
puts("123");
return 0;
}
设置了sock_filter结构体数组。这里为什么是一个结构体数组呢?
结构体数组:
数组中的每个元素都是一个结构体
因为我们看到里面有BPF_STMT和BPF_JMP的宏定义,其实BPF_STMT和BPF_JMP都是条件编译后赋值的sock_filter结构体
sock_filer结构体:
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code,bpf指令码
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
//seccomp-data结构体记录当前正在进行bpf规则检查的系统调用信息
struct seccomp_data{
int nr;//系统调用号
__u32 arch;//调用架构
__u64 instruction_pointer;//CPU指令指针
__u64 argv[6];//寄存器的值,x86下是ebx,exc,edx,edi,ebp;x64下是rdi,rsi,rdx,r10,r8,r9
}https://www.cnblogs.com/L0g4n-blog/p/12839171.html
# 2.seccomp库函数
SCMP_ACT_ALLOW(0x7fff0000U) 黑名单外的进程可以被执行(黑名单内的不能执行)
SCMP_ACT_KILL( 0x00000000U) 白名单外的进程被杀死
__int64 sandbox()
{
// 两个重要的宏,SCMP_ACT_ALLOW(0x7fff0000U)SCMP_ACT_KILL( 0x00000000U)
// seccomp_init初始化,参数为0表示白名单模式,即没有匹配到规则的系统调用都会杀死进程,默认不允许所有的syscall
//参数为0x7fff0000U则为黑名单模式,在名单里的会被杀死
v1 = seccomp_init(0LL);
if ( !v1 ) //初始化失败,v1<=0
{
puts("seccomp error");
exit(0);
}
// seccomp_rule_add添加规则
// v1对应上面初始化的返回值
// 0x7fff0000即对应宏SCMP_ACT_ALLOW(黑名单)
// 第三个参数代表对应的系统调用号,0-->read/1-->write/2-->open/60-->exit
// 第四个参数表示是否需要对对应系统调用的参数做出限制以及指示做出限制的个数,传0不做任何限制
seccomp_rule_add(v1, 0x7FFF0000LL, 2LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 0LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 1LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 60LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 231LL, 0LL);
// seccomp_load - Load the current seccomp filter into the kernel
if ( seccomp_load(v1) < 0 ) //load成功则返回0,这里load失败会执行if内部函数
{
// seccomp_release - Release the seccomp filter state
// 但对已经load的过滤规则不影响
seccomp_release(v1);
puts("seccomp error");
exit(0);
}
return seccomp_release(v1); 释放
}
https://blog.csdn.net/A951860555/article/details/116738676
这里给出关于seccomp_load的定义:
#include <seccomp.h>
typedef void * scmp_filter_ctx;
int seccomp_load(scmp_filter_ctx ctx);
Link with -lseccomp.DESCRIPTION:
Loads the seccomp filter provided by ctx into the kernel; if the function succeeds the new seccomp filter will be active when the function returns. 函数返回时过滤开始运行【seccomp_load是应用过滤,seccomp_reset是解除过滤。】
返回值:Returns zero on success or one of the following error codes on failure;成功时返回 0,失败返回对应错误代码
https://man.archlinux.org/man/seccomp_load.3.en#DESCRIPTION
seccomp_rule_add是添加一条规则
int seccomp_rule_add(scmp_filter_ctx ctx,
uint32_t action, int syscall, unsigned int arg_cnt, ...);arg_cnt表明是否需要对对应系统调用的参数做出限制以及指示做出限制的个数,如果仅仅需要允许或者禁止所有某个系统调用,arg_cnt直接传入0即可,seccomp_rule_add(ctx, SCMP_ACT_KILL, SCMP_SYS(execve), 0)即禁用execve,不管其参数如何。
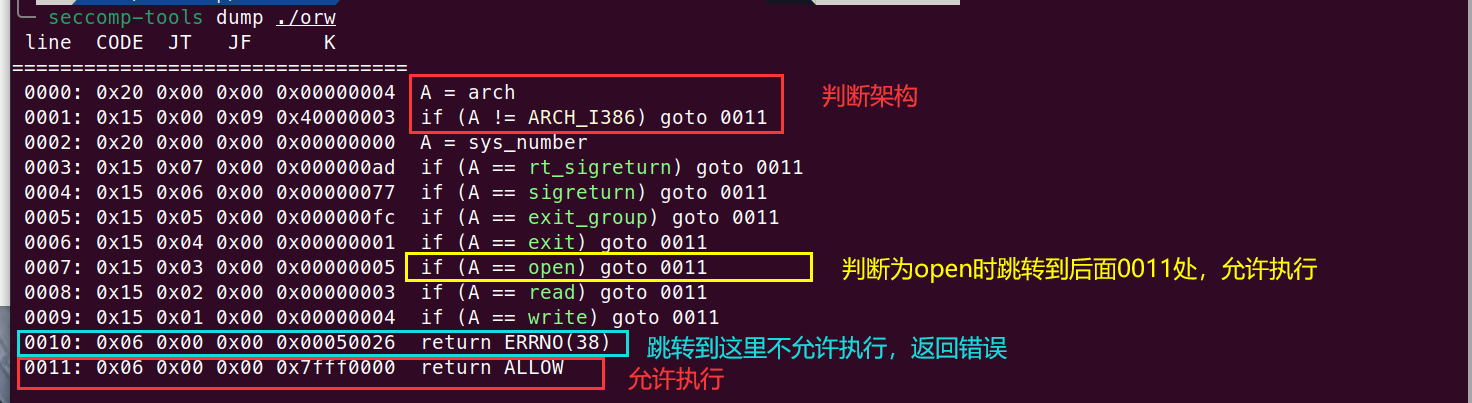
# 3.使用seccomp-tools
命令:
seccomp-tools dump ./pwn
此处用buuctf例题 orw 说明:
# 4.绕过
一般运用orw函数的方式进行读取flag
# 5.注意
当使用了prctl(4, 0)时
4对应的宏是PR_SET_DUMPABLE,第二个参数为0的话则不能被dump,为1可以被dump。换句话说,该程序我们无法使用seccomp-tools dump ./pwn来查看其系统调用情况,只能靠阅读代码分析。同时在进行gdb调试时,执行到prctl(4, 0)这行时程序也会被终止。不过只要以root身份执行,那么secccomp-tools和gdb调试都没问题,估计应该是限制了一般身份用户的dump行为